

文本中隐含的跨境资金流动信息 ——基于文本大数据分析构建跨境资金流出压力指数
【内容摘要】:防范短期跨境资本流动风险是金融外汇管理部门的一项重要工作,对短期跨境资本流动进行有效管理的前提是对未来跨境资金流动的方向和强度进行有效测度。本文通过收集和清洗大量财经类文本数据来构建经济金融中文语料库,在此基础上使用词法分析和机器学习相结合的混合方法对文本进行语义分析,完成文本正负情感倾向标注,进而构建跨境资金流出压力指数。实证研究发现,通过该文本分析方法所构建的跨境资金流出压力指数对未来跨境资金流出规模的变动具有一定预测能力,并且频率为周的高频跨境资金流出压力指数预测能力更强。
【关键词】:文本挖掘 语义分析 跨境资金流出压力指数
一、引言
测度跨境资金流动压力的传统方法主要依赖于经济增长率等宏观经济指标以及购售汇数据等微观主体行为指标,此类数据在更新频率、获得时效等方面存在一定局限。近年来,随着微博、微信等新媒体的兴起,信息传播的速度越来越快,各类专家、学者通过自媒体平台发表其对经济形势、金融市场、国际关系的观点,其中隐含的情绪往往对市场主体的跨境资金摆布行为产生潜在影响。在此背景下,借助机器学习对自媒体上的大数据文本进行分析,为衡量跨境资金流出压力打开了一扇新窗口。通过对网络上海量非结构化文本数据进行文本分析,构建高频跨境资金流出压力指数,有助于刻画市场主体摆布跨境资金的特征,在一定程度上反映市场预期、情绪变化对跨境资金流动的影响,与传统的跨境资金流出压力测度方法形成相互补充。
二、分析经济金融领域中非结构化文本数据的情感倾向
文本分析技术多应用于市场情绪度量、市场情绪指数的构建。例如,通过对博客、股吧、贴吧的留言进行语义分析,探究文本中所表达的投资者情绪、观点和看法等。近年来,部分研究开始将文本大数据分析引入宏观经济领域,使用机器自动统计各类媒体新闻中同时包含经济(economic/economics)、不确定(uncertain/uncertainty)和政策(policy)三类词语的月度文章数量,构建衡量经济政策不确定性的指数。本文尝试将这一方法引入跨境资金流动分析,通过将词法分析和机器学习相结合,对微信上的非结构化文本进行语义分析,并对文本所隐含的正负情感倾向进行快速标注。
第一步,清洗数据并建立经济金融中文语料库。选取微信公众号上经济金融领域相关研究机构和专家学者所发表的观点明确的文章,通过收集、整理、去重,得到4万余个文本数据,以此形成经济金融中文语料库。每条文本数据包含发布时间、阅读量等结构化数据,也包含标题、正文等非结构化数据,时间跨度从2014年10月到2021年9月。
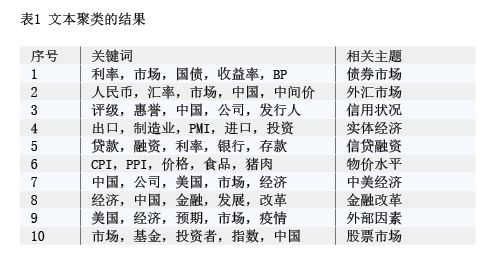
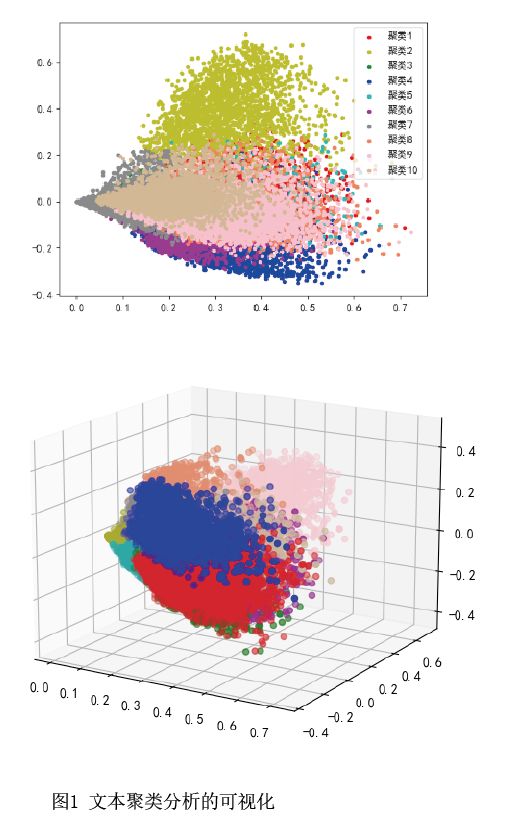
第二步,对文本主题进行聚类。首先,对所有文本进行分词,并标注词性,提取文本统计特征TF-IDF值(词频-逆向文件频率),将文本转化为聚类模型可以处理的特征向量,为了尽量减小特征矩阵的维度,只使用文本中的名词类词汇(包括名词、名动词、名形词)参与聚类,根据每类文本中统计特征最明显的五个关键名词类词汇(见表1)来确定此类文本的主题。然后,使用K-means无监督算法对文本进行聚类,并使用截断奇异值分解(Truncated SVD)降维方法,将每篇文章的特征向量映射到二维和三维空间中,每个点代表一篇文本,以直观展现文本聚类的效果。如图1所示,本文所选取的文本数据在每一类别上的边界较为清晰,说明聚类是有效的。
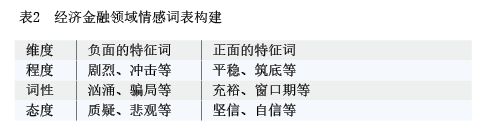
第三步,建立经济金融领域情感词表。常用的情感和语义词典包括知网情感词典(HOWNET)、台湾大学简体中文情感词典(NTUSD),但这类情感词汇多应用于生活中,难以适用于经济金融领域。鉴于经济金融领域的负面情感是出于对不确定性和风险的厌恶,本文先通过人工方法从程度、词性、态度三个维度列出反映经济金融领域情感特征的核心关键词(见表2),然后借助词向量工具word2vec,利用上述经济金融语料库训练一个词向量模型,以此找出与核心关键词相似度较高的词汇,得到一个包含114个正面词汇以及164个负面词汇的经济金融领域情感词表。
第四步,使用词频统计方法对文章情感倾向进行打分。对文本内容中正面词汇和负面词汇出现次数进行统计,出现正面词汇加一分,出现负面词汇减一分,选取特征明显(打分大于等于10分以及小于等于-13分)的文本,分别标注正面情感和负面情感。
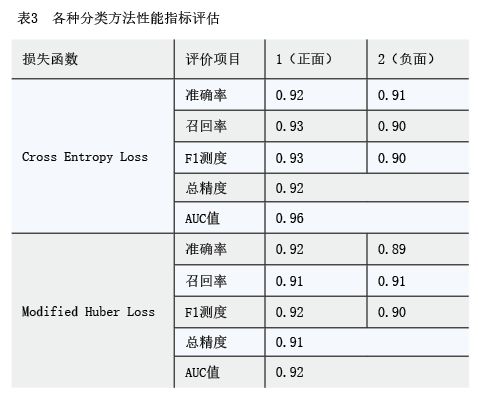
第五步,使用特征明显的文本训练分类器模型。使用词向量工具doc2vec将已标记情感的文本转化为特征向量,并以70%和30%的比例将文本分为训练集和测试集,使用训练集训练一个随机梯度下降分类器(SGD分类器),其可以用于预测二分类问题,对剩余特征不明显的文本正负情感进行预测。分别选取交叉熵损失函数(Cross Entropy Loss)和调整后的Huber损失函数(Modified Huber Loss)作为分类器的损失函数,用测试集来测试不同损失函数的分类器性能,若分类器的AUC值越大,表明分类效果越好。如表3所示,两种损失函数的分类器AUC值分别为0.96、0.92,说明使用交叉熵损失函数的分类器效果更好。
第六步,使用分类器对剩余文本情感进行预测。将剩余文本(得分在-13分和10分之间)转化为特征向量,并使用训练得到的SGD分类器模型完成对所有文本正负情感倾向的标注。
三、使用负面情感文本构建跨境资金流动压力指数
鉴于跨境资金的流出压力与负面情感具有更多的联系,因此本文选取五类表达负面情感的文本来构建跨境资金流出压力指数(见表4)。同时,由于文本需要被阅读后才能向阅读者传递情感,因此本文使用文本对应的阅读量来刻画各类文本信息对市场情绪的潜在影响程度大小,以此作为影响跨境资金流动的权重。

具体而言,将五类文本主题中同一天内所有表达负面倾向的文章的阅读量直接加总(数据时间为2015年5月至2021年9月),得到每日负面情感文本阅读量数据,在此基础上,将该日度阅读量数据变频为月和周,rmt表示所有负面倾向文本在第t月的阅读量数据,rwt表示所有负面倾向文本在第t周的阅读量数据。接着,对阅读量的时间趋势作标准化处理,采用移动平均的方法(月度数据采用6期的移动平均,周数据采用24期的移动平均)分离出阅读量的增长趋势rm0t和rw0t。rmt/rm0t即为剔除时间趋势后的