

基于倾向得分匹配法的跨境贸易投资高水平开放试点成效评估
【内容摘要】2021年末,国家外汇管理局在浙江省宁波市北仑区等4地率先开展跨境贸易投资高水平开放试点。本文立足“更开放”与“更安全”的试点目标,构建三级试点评估指标体系,并使用一线调研数据与倾向得分匹配法开展“反事实”实验。研究显示,高水平开放试点显著提升了市场经营主体的便利化体验,增强了外汇风险防控能力,但同时存在部分试点政策惠及面较窄、市场经营主体获得感不高、银行事后管理压力较大等问题。本文建议推行分类分级管理,发挥自律机制作用,探索建立信息共享与尽职免责机制,推动银行展业转型升级,加强监管能力建设,推动试点政策红利不断释放。
【关键词】高水平开放 试点政策评估 倾向得分匹配法
一、引言
2021年末,国家外汇管理局在上海自由贸易试验区临港新片区、广东自由贸易试验区南沙新区片区、海南自由贸易港洋浦经济开发区和浙江省宁波市北仑区(以下简称北仑试点区域)4地开展跨境贸易投资高水平开放试点(以下简称高水平开放试点)。高水平开放试点一次性推出涵盖跨境贸易与投融资在内的13项改革措施,主要内容集中在三个方面:一是优化审核方式,重塑业务管理流程。4项跨境贸易便利化措施,聚焦银行管理转型,推动银行真实性审核从事中单证审核向全流程、差异化风险管理转变,最大程度“减材料、减手续”,提升跨境资金结算效率;4项跨境投融资便利化措施,按照“应简尽简、能放则放”原则,精简资本项目管理流程,将相关登记业务改由银行办理,大幅提升资金使用的自主性与灵活性。二是突破现行政策限制,拓展跨境投融资渠道。5项跨境投融资自由化措施在机构准入、业务准入、规则完善等方面积极探索,拓宽企业跨境投融资渠道,稳步推进金融市场双向开放。三是探索构建与高水平开放相适应的风险防控机制,推动风险防控更加精准有效。在推动试点有效落地的基础上,创新风险防控机制,加大对高风险主体、高风险业务的监管力度,提高风险管理的指向性、精准性,确保试点平稳有序推进。及时、客观评估试点政策效果,对于后续试点经验复制推广和政策创新具有重要意义。
二、基于倾向得分匹配法的实证研究
本文使用倾向得分匹配法,找出与试点企业特征相似的非试点企业进行比较分析,以克服企业经营、宏观环境等可观测变量对评估结果的干扰,从而提升试点评估的客观性与科学性。
(一)试点评估指标体系与问卷调查结果
试点评估指标体系。客观衡量试点政策执行效果,有赖于科学的评估指标。本文从“更开放”“更安全”两大试点目标出发,构建三级试点评估指标体系(见表1)。一级指标由业务便利性与业务安全性2个指标构成,由二级指标百分制换算得到。二级指标包括便利化感受、业务办理时间、单证审核便利、事后管理有效性、内控完善情况、事前展业有效性6个指标,由三级指标经权重调整得到,二级、三级指标权重则由行业专家根据地方跨境收支结构和企业外汇业务办理情况集体赋值。三级指标共计14个,通过问卷调查获取。
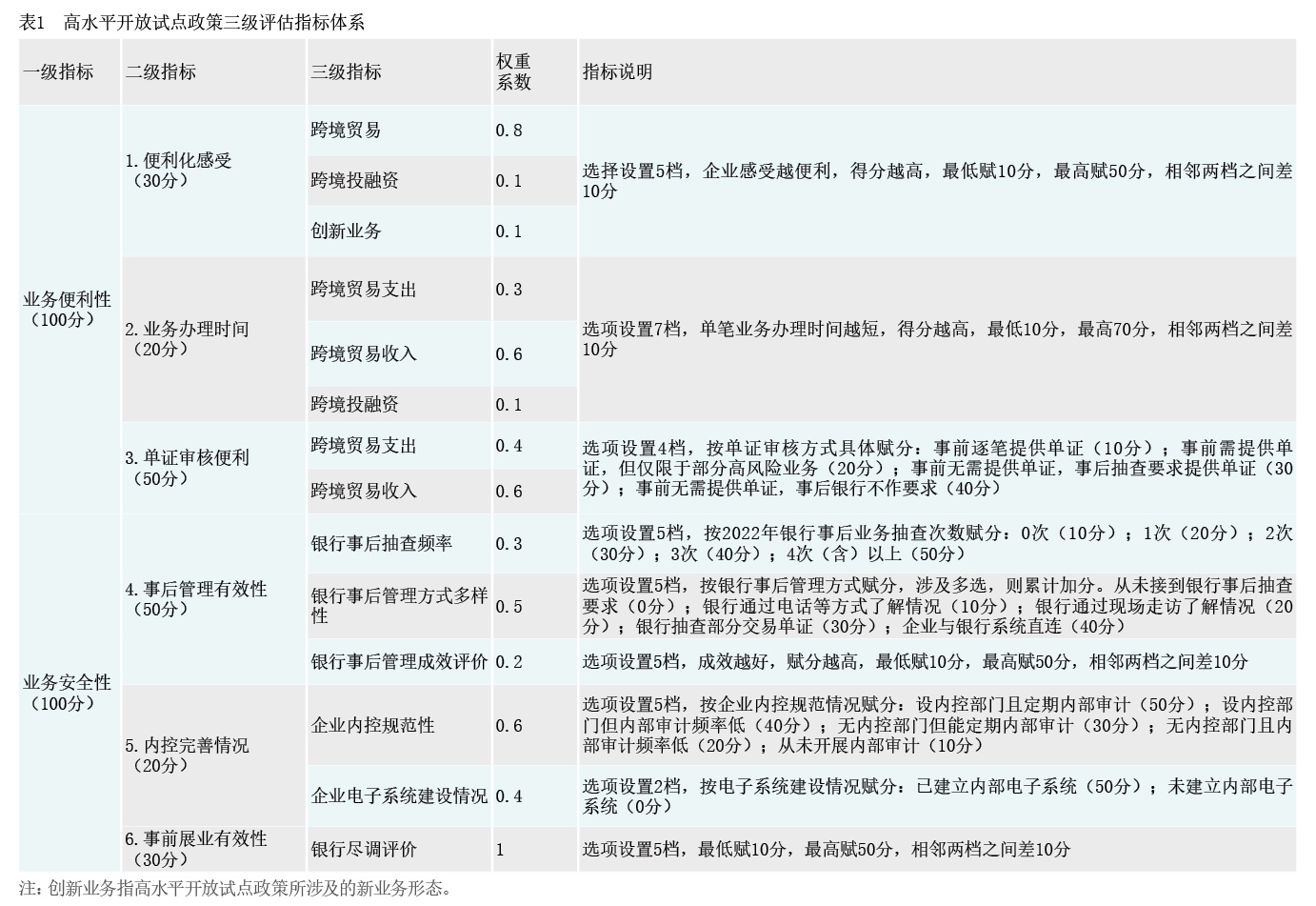
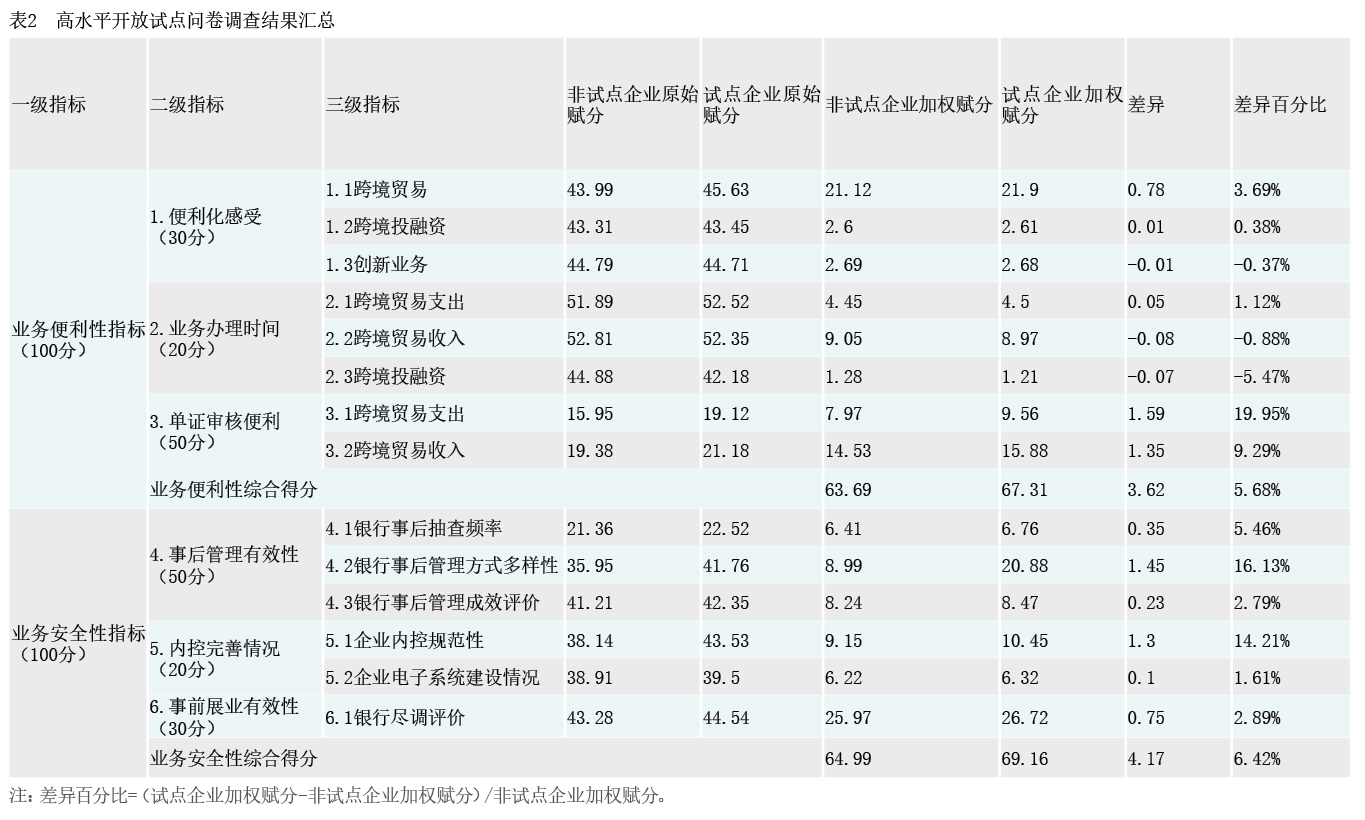
问卷调查结果。本文对219家试点企业和471家非试点企业进行问卷调查,非试点企业由随机抽样产生。最终回收有效问卷457份,包括试点企业119家和非试点企业338家。试点企业在两个一级指标上的表现均优于非试点企业(见表2)。其中,试点企业对业务便利性的综合赋分高出非试点企业3.6分,对业务安全性的综合赋分高出非试点企业4.2分。
(二)倾向得分匹配法建模
第一步,计算倾向得分值。本文使用Logit 模型计算倾向得分值(P值),P值代表特定条件下样本企业参与试点的概率。假设随机变量的累积分布函数为“逻辑分布”的累积分布函数:
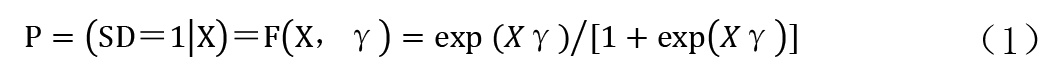
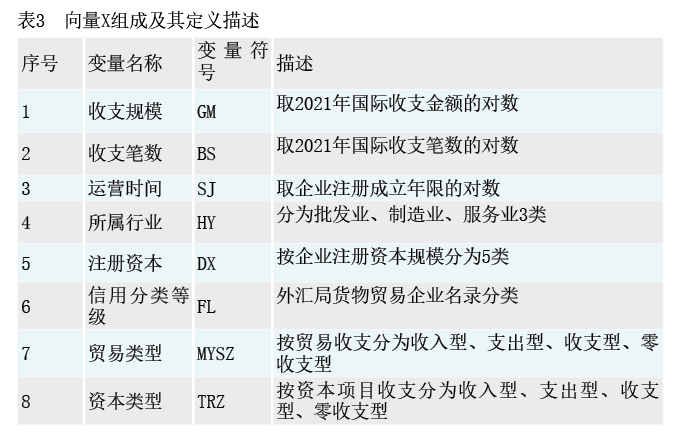
其中,向量X由影响企业参与试点的一系列变量构成。本文使用收支规模、运营时间、信用分类等级等8个协变量(见表3),γ为相应的参数向量。获得(1)式的参数估计值后,进一步通过模型预测得到企业参与试点的概率值P。
第二步,匹配出可比样本。本文根据(1)式得到的P值,使用最邻近匹配算法,按1:1的比例,在非试点组中匹配与试点组特征相似的企业,形成样本组SD,并将试点组记为SD=1,非试点组记为SD=0。
第三步,计算单个企业的试点政策效应。由于现实中无法观测试点企业在未参与试点情况下的表现,因此本文使用第二步匹配得到的非试点组表现来替代,计算出企业参与试点前后的政策效应:

第四步,计算试点政策平均效应。对试点组每个企业进行(2)式测算,并将结果汇总平均,得到试点政策的平均效应δ。其中,N1代表试点组样本数。
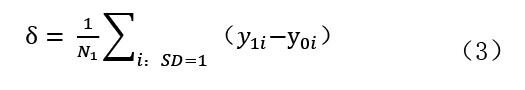
(三)实证分析结果与模型检验
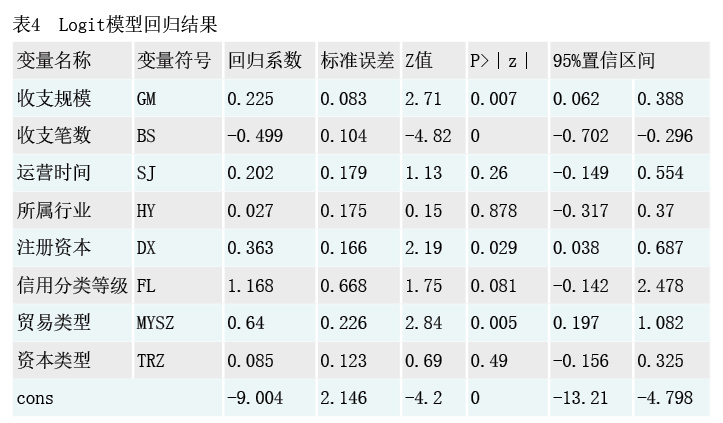
倾向得分值估计结果。设定可能与企业参与试点的概率具有较高相关性的8个协变量,模型联合检验得chi2(8)=68.21,Prob>chi2=0.00,可知模型具有显著性。结果显示,在95%的置信区间下,收支规模、收支笔数、注册资本、贸易类型4个协变量对企业是否参与试点具有显著影响(见表4)。在90%的置信区间下,信用分类等级对企业是否参与试点具有显著影响。运营时间、所属行业、资本类型3个变量对企业是否参与试点的影响不显著。
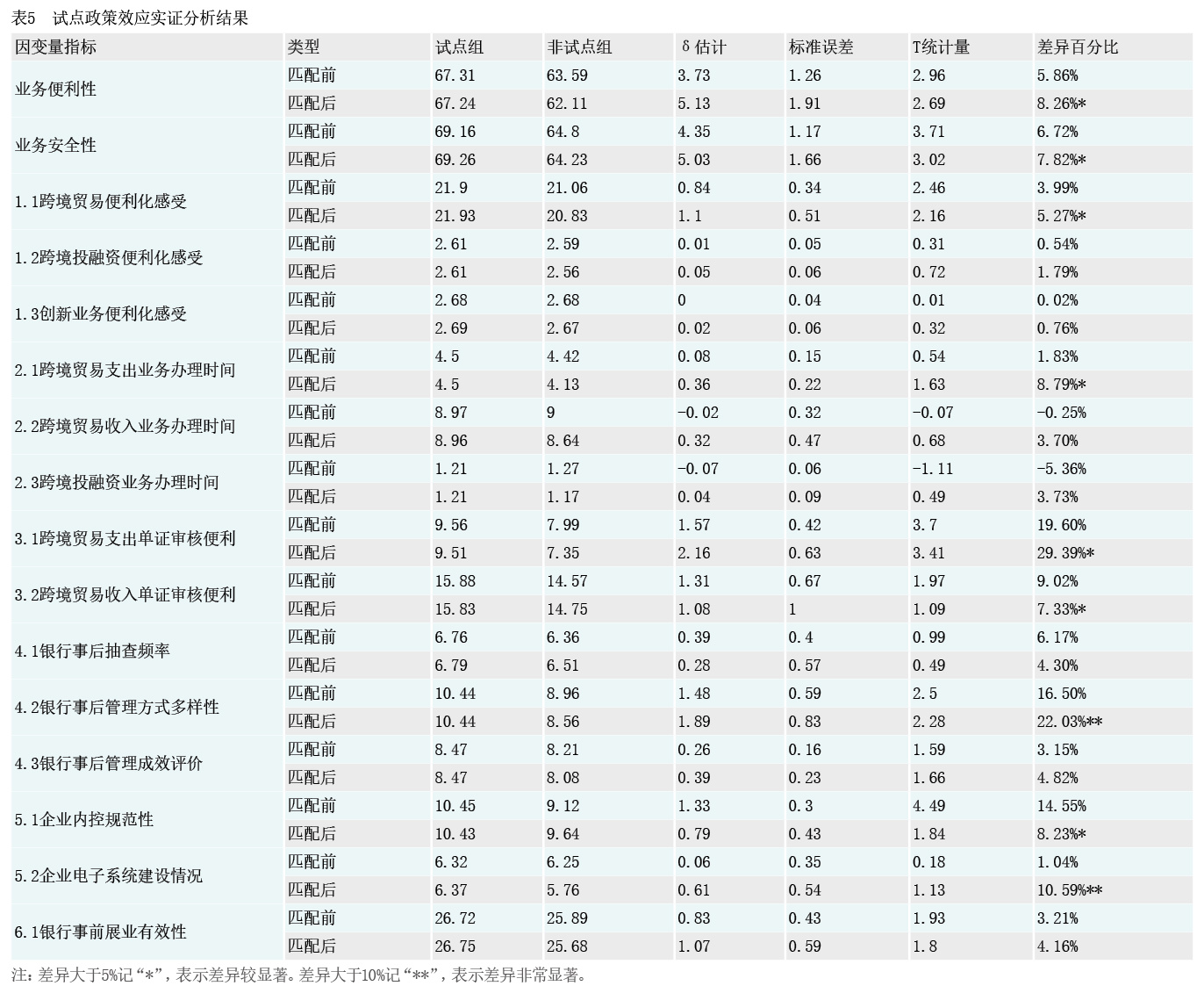
试点政策效应估计结果。由于非试点组样本容量不大,本文选择有放回匹配且允许并列,使用STATA倾向得分匹配模型进行实证分析,最终得到各维度的政策效应(见表5)。
模型有效性检验。倾向得分匹配法要求样本满足依条件独立和共同支持条件。本文采用匹配平衡检验模型是否满足依条件独立,观察匹配后的试点组与非试点组之间的标准偏差。现有文献认为标准偏差的绝对值应小于20,且标准偏差值越小,样本匹配效果越好。本文所有变量的标准偏差绝对值都小于13.7,说明样本匹配效果较好。此外,Logit模型估计得到的P值均位于[0,1],满足共同支持条件,大多数观测值均在共同取值范围内,匹配时仅损失20个样本。
三、研究结论
基于上文分析,结合对41家银行的问卷、座谈调查,本文得出以下结论:
(一)从企业维度看试点政策成效
银行单证审核优化、贸易结算办理提速,支出端表现尤为明显。研究显示,试点组对业务便利性的综合赋分为67.2分,高于非试点组5.1分,试点后业务便利化水平提升了8